来点语言律师题,之前刷 reddit 看到的,作者取了个非常中二的名字(,空闲时间做了把他搬过来了。
Assigning to references
Does this work? If it doesn’t, why and what’s the easiest fix?
|
|
What about this one? If this one doesn’t, why and what’s the easiest fix?
|
|
第一个是对的,第二个是错的,为什么呢?
根据 decltype 的规定
,我们可以推导出:
| 写法 | decltype 推导结果 |
语法分类 | 推导出的返回类型 | 结果 |
|---|---|---|---|---|
return fields...[Idx]; |
规则 1:decltype(entity) |
id-expression | int (传值) |
产生 prvalue,报错 |
return (fields...[Idx]); |
规则 2:decltype(expression) |
lvalue | int& (传引用) |
产生 lvalue,合法 |
在不带括号时 fields...[Idx] 是一个 id-expression。其被推导为 decltype(entity) 里的 entity。对于结构化绑定,编译器会直接提取它底层绑定的变量类型。在这里,底层类型是 int。因此,decltype(auto) 将函数返回值推导为 int。函数返回一个 prvalue,你不能对一个 pvalue 赋值。
而我们加上括号后, 括号强制改变了它的语法属性,使其变成了一个左值表达式,此时编译器触发 decltype(expression) 规则。因为该表达式是一个 lvalue,标准规定 decltype 必须将其推导为引用类型 int&。因此,函数返回了对原始数据的引用,赋值操作完全合法。
我找到一篇写的很详细的博客 C++ value categories and
decltypedemystified: https://www.scs.stanford.edu/ ~dm/blog/decltype.html
Defaulted equality
Does this work?
|
|
Does this work?
|
|
<=> 是 cpp 20 引进的一个新特性
,他的核心是,比较时不返回 bool,而是返回一个序关系。这是一个很方便的特性,使用它,在重载运算符上就变得十分方便。是我十分喜欢的一个抽象。
这是一个例子:https://godbolt.org/z/34EjovMca
在这一节 的 3.2 中,说明:
If the member-specification does not explicitly declare any member or friend named operator==, an == operator function is declared implicitly for each three-way comparison operator function defined as defaulted in the member-specification , with the same access and function-definition and in the same class scope as the respective three-way comparison operator function, except that the return type is replaced with bool and the declarator-id is replaced with operator== 机翻:如果成员声明没有显式声明任何名为 operator== 的成员或朋友,则对于在成员声明中定义为默认的三向比较运算符函数,会隐式声明一个 == 运算符函数,具有相同的访问权限和函数定义,并在相应的三向比较运算符函数的相同类作用域中,但返回类型被替换为 bool,声明标识符被替换为 operator==
在第一个例子中,<=> 被声明为了 default,同时 == 也会被声明。但是在第二个例子中,由于我们没有给出 <=> 的默认实现,编译器不会为我们声明 == 函数,就算我们在后面补充上了 <=> 的实现,== 依旧依赖于我们手动实现。
Specialization fun
You have this in your header:
|
|
How can this bite you?
It’s alright if only one TU includes this header.
But if more than one does, the linker might complain
on a CWG 2387-conforming implementation:
a fully specialized variable template (the one for std::vector<bool>)
is a variable definition, so all the usual variable linkage rules apply.
The fix is to add inline to that line only:
|
|
Also, constexpr doesn’t help: unlike constexpr functions,
constexpr variables are not implicitly inline.
Bonus points for …
… immediately thinking “unless they are static class data members, of course!” when reading the previous sentence.
requires-constrained return types
|
|
Dummy<> does not typecheck. Do you expect it to not typecheck? Why it does not typecheck and how to fix it?
Solution constraint
No, you are not allowed to hide it under auto + deduced type. For the actual type in the actual use case that prompted writing this, the return type then needs to be written in every branch, and it’s annoying, and also reduces discoverability of the API.
看似可以完美的触发 SFINAE,但是不妨注意到,在 std::optional<Args...> foo 中,如果 Args...为空,这里就是一个 hard error,正如编译器给出的 Too few template arguments for class template 'optional'。
如何修复呢?
我们可以用一个基类 DummyBase 来包装,再根据包的大小特化 Dummy ,如 https://godbolt.org/z/vdPsojqv3
我们也可以用一个辅助类型来包装,确保 optional 里面永远不为空,就像这样:
|
|
Bonus question
Some usual approaches don’t work:
- Making
fooitself a template with a default template parameter, likeis not well-formed since packs can’t have default values.1 2 3template<typename... MyArgs = Args...> requires(sizeof...(MyArgs) == 1) std::optional<MyArgs...> foo() - Using something like
template<typename T = std::tuple_element_t<0, std::tuple<Args...>>and then havingstd::optional<T>in the “unary”foo()case:std::tuple_element_thard-errors on out-of-bounds index instead of merely being SFINAEd away. - A C++26 variation of that with pack indexing with
template<typename T = Args...[0]>: out-of-bounds in pack indexing is also somehow a hard error instead of being SFINAEd away.
Given this, what can you say about orthogonality and well-thought-ness of C++?
hhh, 我不好说。
Is this valid?
|
|
Answer: see this bugzilla entry .
为了让我们在类成员函数中使用后面才会定义的变量,编译器不会立即处理两种内容,直到整个类结束后才会构造,这里第一是类成员变量的初始值,第二是函数的默认构造函数。
在这个代码中,由于 doSmth 还在类中,我们 Nested 不存在构造函数,一旦我们写下 const Nested& = Nested{},就代表我们需要 Nested 有构造函数。这是什么,循环依赖了,万测尽,悲。
理解了原理,似乎我们也很好修改,只需要给 Nested 手动添加一个构造函数就行了。但是,如下代码依然会有错误:
|
|
因为将构造函数声明为 default 和直接表明我们这个 Nested 类有构造函数 Nested() {}; 是不一样的,default 不代表 Nested 类一定有构造函数,这取决于类的实现。
值得一提的是,msvc,会编译成功,哈哈哈哈。
Some covariance (协变)
Is this valid?
|
|
Sure: this is covariance in action.
What about this?
|
|
Yep, also good: in some sense, Base* is a subtype of const Base*.
And, of course, Derived* would’ve worked too.
Now, this is surely valid too, right?
|
|
Nope: non-class types play by different rules, because otherwise the language would’ve been too consistent (see https://eel.is/c++draft/class.virtual #8).
那么问题来了,我们要怎么正确是实现呢?
一个显然的思路是包装一下我们的 int,但这样不够通用而且太繁琐了。
额,如果忽视 runtime 环境的话,用 CRTP 可以很好的解决这个问题:
|
|
还有别的方法吗?我们也可以这么处理:
|
|
这么写显然很丑陋。。
constexpr string literals
Does this compile?
|
|
Here the answer is easy: it’s an open question, discussed in CWG #2765 .
可能会有 Static assertion expression is not an integral constant expression ,因为在比较字符串地址。
如果要比较,请不要使用 auto。
When is this function safe or unsafe to use?
|
|
u1s1, 有点幻视:
|
|
It’s safe for class types and unsafe for, say, ints.
For some reason the standard threats them differently, so
|
|
Finding the corresponding clauses in the standard is left as an exercise for the reader.
Maps of non-copyable, non-movable types
Suppose you have a type that’s not copyable nor movable, like
|
|
假设你需要一个把从 int 映射到 ThreadedResource 的 hashmap。一个方法是使用 shared_ptr 来包装一下 ThreadedResouce。如 std::unoredred_map<int, std::shared_ptr<ThreadedResource>>。空指针表示这里没有映射。
这很麻烦(?)因为它会有额外的内存开销和访问,导致了性能下降。
你能做的更好吗?
一个可能的答案是使用 std::optional,它可以更清晰的表达 “no value”。
因为对象不能移动,我们得使用分段构造 piecewise_construct:
|
|
请注意,ThreadedResource 字段的顺序是 mutex 在 handle 之后,
因此无需向 mutex 传递初始化器,一切都能正常运行。
Incrementing enums
Is this valid?
|
|
虽然我们不能对枚举自增,但是我们可以重载枚举的 ++ 运算符。
比如:
|
|
operator new
Is this valid?
|
|
How about this?
|
|
显然不对,new 操作符是隐式 static 的,而此时 n 还没有创建完成。既然对象不存在,哪里来的分配内存?对于虚函数来说,此时同理没有 vtbl。
How are these two functions different?
|
|
mkT1 是复制列表初始化
,mkT2 是直接列表初始化。
他们直接的区别在于对 explicit 构造函数的处理。T1 函数不允许调用标记为 explicit 的构造函数。
并且在 c++ 17 之前,T{} 会创建一个临时对象,这导致 std::mutex 这种无法使用。
Is this code valid?
|
|
这同样涉及到 cpp 的初始化,在 c++20 之前,一个类被视为聚合体,如果:
- 没有用户提供的构造函数
- 没有私有或保护的非静态数据成员
- 没有基类,没有虚函数
在这里,Foo() = delete 属于用户声明,但不属于用户提供。所以他被视为聚合体。在聚合初始化中,编译器会绕过构造函数,直接给成员赋值而不需要构造函数。
这就导致了上面这种看起来很不合理的代码在 c++17 标准下可以编译通过。
btw, c++20 修改了聚合体的定义,以上代码无法在 c++20 以上编译。
(^=…=^)
What does this code do, and on what features of C++17 does it rely?
|
|
这个标题幻视我们的反射 [:O_o:]
这个代码很难读,实际上 cpp 模板里面有很多这样很难读的代码。。。。。。
它依赖了变长参数模板,折叠表达式,赋值运算符的评估顺序。简单的来说,如果我们调用 foo(func, 1, 2, 3) 其会依次调用 func(3) func(2) func(1)。
我们详细讲解一下。
假设我们调用 foo(f, t1, t2) ,(_ = ... = (f(ts), 0)) 是一个二元左折叠。其结构 (Init op ... op Pack)。
展开后,看起来像这样: ((_ = (f(t1), 0)) = (f(t2), 0))。根据 c++17 标准,在表达式 A = B 中,B 在 A 先执行。所以先执行 t2 然后再 t1。
这个代码有什么问题呢?当我们偷偷重载了 operator, 或 operator= 的时候,就有可能有问题。
当然,还有一个最大的问题,就是可读性太差太差了。。。
Conceptual concepts
Assume the following declarations:
|
|
-
Is
f(1, 2)valid? If yes, what would it print? -
What if
Trivial<T> && Trivial<U>is replaced byTrivial<T> && Trivial<T>in the second definition? -
What about
Trivial<T> || Trivial<U>? -
What if the definition of
Trivialgets “inlined”, replacing allTrivial<T>s withsd::is_trivial_v<T>?
答案是 2,
|
|
1 和 ambiguous。
Fun with fun templates
What does bar1 print?
|
|
What if we reorder the definitions, as in bar2?
|
|
Can we still specialize the first template after we’ve introduced the second one?
Yep:
|
|
把这个和上面那个放在一起来讲吧。当初学模板元做的笔记:
在类模板的特化过程中,编译器会先将模板转化成函数模板,借助函数模板重载来决定优先级。
函数模板偏序规则:
如果模板 A 能够处理的所有情况,模板 B 都能处理。而模板 B 能处理的情况,模板 A 未必能处理。则模板 A 比 B 更特化。
文章的意思大概是:编译器捏造一个类型 U,用类型 U 带入模板 A,生成一个具体的函数签名。 然后用这个函数签名,去试图匹配模板 B 如果能匹配,则说明 A 比 B 特化。反过来做一遍,就能够比较 A 和 B 的特化程度了。
|
|
如果我们要比较 #1 和 #2 的特化程度,首先,尝试 #2 带入 #1 ,我们用一个模板实参 U(比如说 int) 带入 #2。也就是 template <typename T = U> void foo(U *); (foo(int *))然后尝试 U* 带入 #1,也就是 template <typename T> void foo(U *)(可以想象成 foo(int *) 去匹配 #1)此时,#1 的 T 可以被推导为 U*。
然后,我们再尝试用 #1 带入 #2,同理用一个模板实参 U 带入 #1 template <typename T = U> void foo(U); 去匹配 #2,得到 T* = U -> 失败
综上得出:#2 的特化程度比 #1 高。
函数模版既可以重载,又可以全特化,函数模板的每一个重载都是主模板。实例化过程中,先进行重载决议,然后再特化匹配。也就是说,在重载决议阶段,只考虑主模板,不考虑主模板的全特化。选择主模板后,才进行特化匹配。这样的规则会导致:如果模板特化的位置不同,最终匹配到的模板也有可能不同。所以我们不应该使用函数模板全特化,而是使用函数重载。
放在这里就是:
下面的解析是 AIGC。
|
|
foo(&test):- 主模板
#1(T=int*) 和#2(T=int) 都在候选名单中。 - 根据偏序规则,
#2比#1更特化($T*$ 优于 $T$)。 - 选择
#2。由于#2在此处没有特化版本,返回 3。
- 主模板
foo<int>(&test):- 指定
T=int。只有#2匹配(foo(int*))。返回 3。
- 指定
foo<int*>(&test):- 指定
T=int*。 #1变为foo(int*),匹配。#2变为foo(int**),不匹配。- 选择
#1。检查#1的特化,发现foo(int*),返回 2。
- 指定
结果:332
|
|
注意:这里的全特化 template<> int foo(int*) 会关联到当前最匹配的主模板,即 #2。
foo(&test):- 选择主模板
#2。检查其特化,发现foo(int*)。返回 2。
- 选择主模板
foo<int>(&test):- 选择主模板
#2。检查其特化,发现foo(int*)。返回 2。
- 选择主模板
foo<int*>(&test):#1匹配,#2不匹配。- 选择
#1。#1在此处没有特化。返回 1。
结果:221
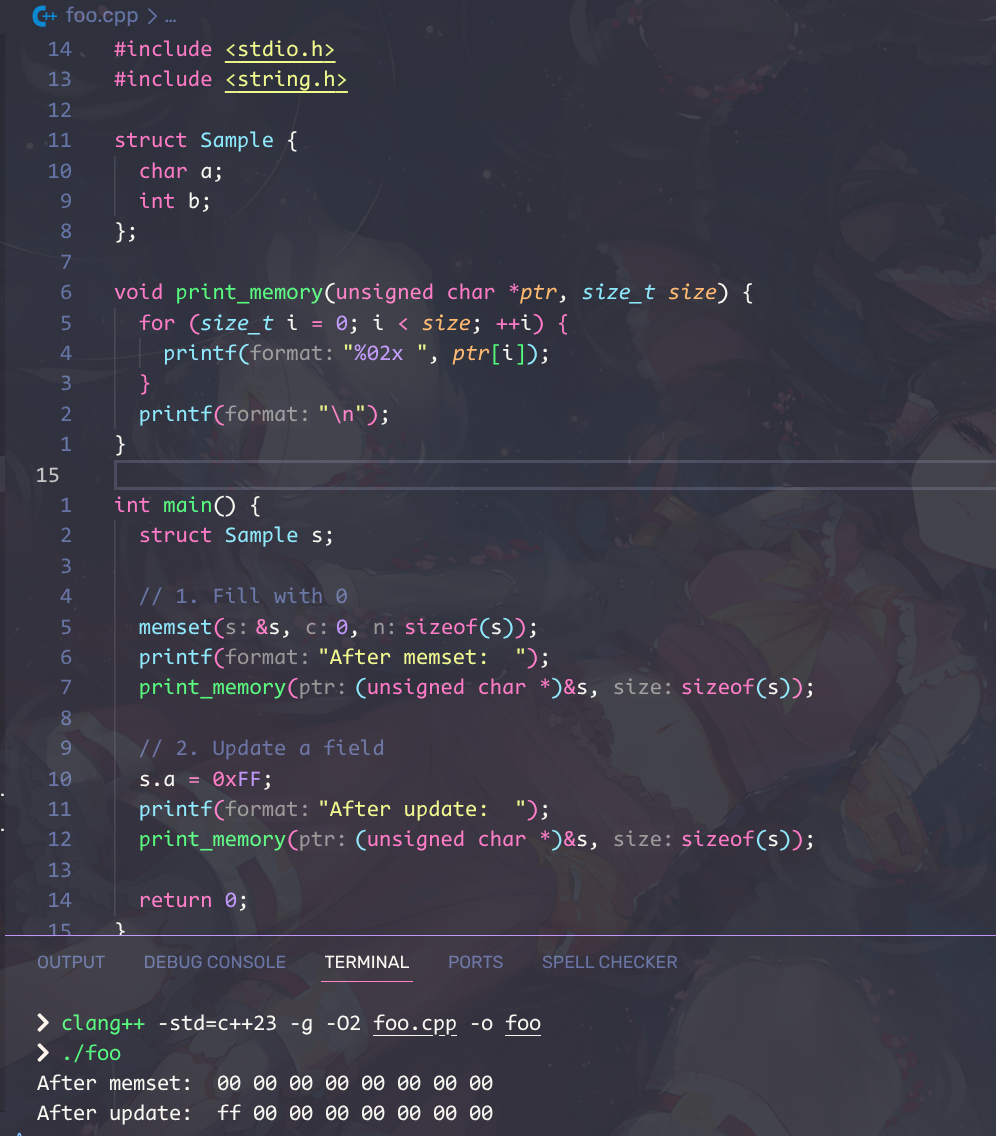
I C memset
Assume an instance of a struct is memseted to zeroes. What would be the value of the padding?
Further assume a field of that structure is updated. What would be the value of the padding after that field? After other fields?
都是未指定的。
为了更加直观的了解这个,我们来看看其内存模型。
假设有这么一个类:
|
|
在我们 memset 完后:
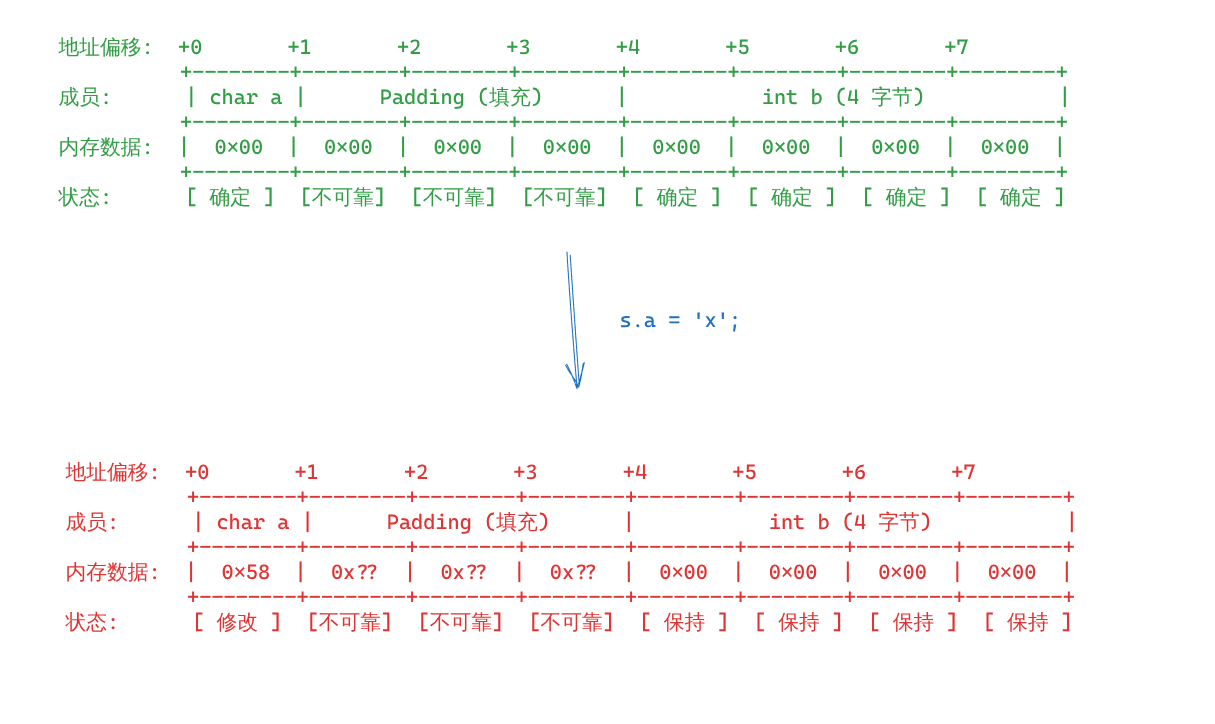
如图,无论是执行完 s.a = 'x'; 前后,填充位的值都不可靠。为什么呢,希腊奶。但既然标准这么规定了,就不要依赖这种行为(真不会依赖吗?)
anyway,在我的电脑上:
Is this code valid?
|
|
What about this one?
|
|
第一个不合法,第二个合法。但是注意不要这么做
|
|
Which lines are UB, if any?
|
|
找了个稍微老一点的 gcc 版本 https://godbolt.org/z/bTE77GEs3
可以观察到 11 21 31 32 全是 ub。
11 12 13 是 ub,这很显然。但 32 为什么是呢?
涉及到 user-provided https://eel.is/c++draft/dcl.fct.def.default 。
根据 c 嘎嘎标准,在类外提供构造函数,这被视为 user-provided 的构造函数,对于 user-provided 的构造函数来说,编译器直接调用该构造函数,不再进行额外的零初始化。
所以,如果类外实现构造函数,最好手动初始化所有成员。
Is this code valid?
|
|
Depends on the C++ version, and whether it is C++ to begin with.
Up until C++17, neither an x object nor an int subobjects are created, and this code is UB.
Starting with C++20, an x object and its int subobjects are implicitly created, and this code is valid.
It always has been valid C code, though.
我以为这是对的(毕竟我只在 c 里面写过这样的代码。
在 c++20 之前,malloc 并不创建对象。访问 p->a 时,该内存地址并没有一个真正的 X 对象存在.对象必须使用 new 显示创建。
如果要正确的写的话:
|
|
Is using this function dangerous?
|
|
What about this one?
|
|
This one?
|
|
Nope, nope, yep.
Why? What’s the crucial difference between these functions? Is there any difference in their types?
Accessing any element of the “array” returned by foo1 and foo2 is fine.
Try doing that to foo3 and you’ll get an UB, since you’ll be using an object whose lifetime has ended!
foo1 and foo2 return a pointer to a string that is, roughly speaking, allocated and stored somewhere in the executable at compile time.
The pointer returned by foo3 references the local array str which is initialized by copying that same string.
This array is local to foo3 and its lifetime ends once the function has returned, hence the UB.
While modern compilers output a warning, what’s a reliable and somewhat general way to check functions like this?
Mark all these functions constexpr and try using them in a constant evaluated context, like static_assert:
|
|
Say, clang outputs:
|
|
What does this print?
|
|
borrowed from Arthur O’Dwyer’s blog, where he also considers this in more detail
输出是 CoreLibrary。
这个应该是一个老生长谈的问题了,不过这里展示的比较隐秘,一般是用 std::swap 来讲解 ADL 和 CPO 的。
CPO 和 tag invoke 是现代 cpp 比较重要的特性,ranges 里面大量使用 cpo 进行实现。
Are these functions different?
|
|
f() 会是好函数吗?(
事实上,f 是 ub, 而 g 没有问题。
borrowed from Daniil Zhuravlev’s blog, where
he explains what language in the C++ Standard makes it UB and shows a proof that function f is fishy
Conclusion
我真是疯了,把这个写完了。你如果问我:“我把这些都学会了,我能变成 cpp 大佬吗”?我觉得不行,毕竟揪着偏门语言特性不放大概率是魔怔人。
累了,放张图。
